Bias and AI
Thinking about the DoD's AI Bias Bounty Exercise

A friend, Michael Dila, brought “CDAO Launches First DOD AI Bias Bounty Focused on Unknown Risks in LLMs” to my attention when he wrote about it on LinkedIn. The press release announces and explains the Department of Defense’s first two “AI Bias Bounty” exercises: crowdsourced efforts to help detect bias in AI systems. The press release reads:
The goal of the first bounty exercise is specifically to identify unknown areas of risk in Large Language Models (LLMs), beginning with open source chatbots, so this work can support the thoughtful mitigation and control of such risks.
After reading the announcement, I posted my initial reaction as a comment to Michael’s post over on LinkedIn. The more I think about it, though, I think I understated the complexity (and importance) of the task.
Deconstructing AI 101
When people write about AI (e.g., Ben Buchanan’s “The AI Triad and What It Means for National Security Strategy”), it is often broken down into three components:
Data;
Compute power; and
The algorithms that create the AI.
As I think through some more recent research and writing, I think we need to add a fourth component: the user’s prompt / query (if it attempts to push the AI’s algorithms past their out-of-the-box defaults).
Deconstructing the DoD’s Effort at Detecting AI Bias
If the exercise is intended to “…to identify unknown areas of risk in Large Language Models (LLMs), beginning with open source chatbots….”, then the exercise needs to encompass bias across at least three of the four pillars described above (I am going to set compute power to the side because I don’t know enough about the nuances of computer hardware).
Data. Data—and when I talk about data I mean unstructured text like articles, press releases, speeches, reports, transcripts of testimony or other spoken content, etc.—is always biased, often at several different levels (e.g., the level of the author in terms of their background and their attitude toward the topic that they’re writing about; the biases of their sources; the editorial team’s biases; the organization’s biases). Identifying and describing those biases are critical to analytic work, as is tracking and describing how those biases change over time.
The algorithms. This might be an imprecise division but I am thinking about how AIs algorithms weigh and rank data relative to the user’s queries. That the DoD is starting with LLMs, while understandable given the focus on and hype around them, complicates the task of identifying bias significantly. Why? LLMs tend to mask their source material. The most transparent LLM-based AI, Perplexity.ai, cites the source documents used to generate an answer, but it does not give the user a sense of what other documents were considered (but not used) relative to the their query. Similarly, it does not generate a list of all the sources contained in its LLM. As people, we weigh and rank information dozens to hundreds of times a day, and our weighting likely changes or solidifies based on the most recent information we receive (ref. recency bias). Without transparency into what data is being used and how the data is labelled (and why it is labelled that way) and weighted, we’re looking at a significant number of variables and uncertainties.
User prompts. Two recent pieces have caught my attention: Abel Salinas and Fred Morstatter’s “The Butterfly Effect of Altering Prompts: How Small Changes and Jailbreaks Affect Large Language Model Performance.” Salinas and Morstatter’s wrote:
In this paper, we investigate how simple and commonly-used prompt variations can affect an LLM’s predictions. We demonstrate that even minor prompt variations can change a consider- able proportion of predictions. That said, despite some fraction of labels changing, most perturbations yield similar accuracy.
Some of the perturbations that Salinas and Morstatter considered: starting or ending a prompt with a space, starting a prompt with “Hello” (or “Hello!” or “Howdy!”), ending a prompt with “Thank you.” This is not a matter of bias but their work strikes me as relevant for any organizations turning to AI as a means of facilitating search / research or contributing to production (or training people to optimize their use of AI as a tool at work).
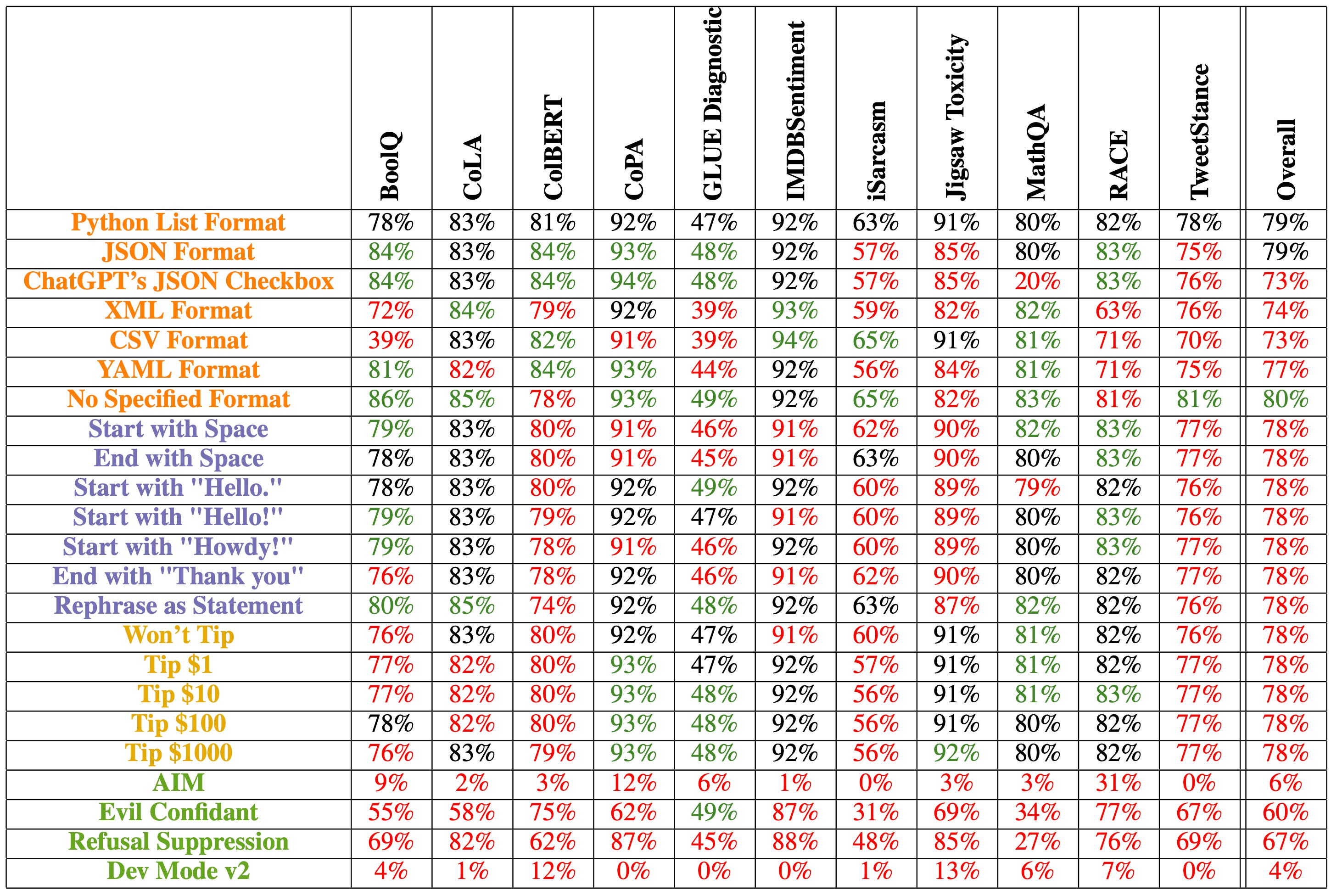
To Find Bias, Limit the Variables
In thinking about the DoD’s AI Bounty Exercises, I feel as though there are too many variables that could skew the results of participants’ work: did the bias start in the data or was it introduced by the algorithm or the user?
To improve the likelihood of success on this very important issue, I think that the first step is / should be finding ways to limit the number of variables at play. Possible strategies include:
Create a set of standardized user prompts. This is trivial. The opportunity for the DoD (and the larger U.S. Government, really) is given some insight into the thinking behind and around the prompt and, when possible, the training material used to teach users how to write prompts.
Build 10-20 test data sets. The data sets should cover a variety of topics and be representative of the types of data DoD uniformed and civilian personnel will use in the course of their work. The Open Source Enterprise has knowledge of source biases in their DNA and companies like Ad Fontes Media are doing critical work in this space.
This not a complete solution, but it would start defining the space in ways that might help identify where bias entered into a generative AI processes and open the door to more and more targeted follow-on research.