Context and AI
What do we mean and why context matters

One of the (many) challenges that I have with artificial intelligence is its lack of a contextual understanding of me as a user.
Let me start by saying that I know that it is unrealistic for a major AI platform to have an understanding of me and my interests, let alone the drivers behind my interests or my goals and objectives for exploring my interests because that it is not what large language models were designed to do. “Remembering” the conversations that I’ve had with an AI is a poor proxy for a deep and rich contextual understanding of me as a user.
Two Types of Context
In thinking about information, I see two types of context:
The first is relationship a piece of information has relative to other pieces of information in the same body of knowledge (or closely related bodies of knowledge);
The second is the place a piece of information has in my personal knowledge base as determined by the information that I have skimmed, triaged, consumed, internalized, and possibly forgotten.
Thus, both types of context are relational and dynamic so context necessarily has a strong temporal dimension to it. In short, context is—or presumes the existence of—a knowledge graph.
Caveat Lector
For those of you who don’t know me, my background is as an intelligence analyst and analytic methodologist who spent a lot of time thinking about the intersections of information, technology, and analytic practice, so much so that I was recruited to run a large flagship program to realign data, information technologies, analytic practice, and customer engagement. When I talk about artificial intelligence, I come at it from the perspective of a high-end analytic user who has more than a passing familiarity with aligning enterprise-grade information technologies as they relate to how experts search for, discover, interact with, and use information.
Large Language Models are Not Knowledge Graphs
Large language models (LLMs) represent an incredible technical achievement that is out of sync with how human experts think.
I’ve pointed to Philip Ross’s “The Expert Mind” (Scientific American, 2006) before and I am likely to continue doing so because it most accurately describes how analysts think in my experience: the hundreds of experts I worked with (and designed systems to support) had an uncanny ability to remember and cite very specific chunks of information (both in terms of content and provenance). Each chunk of information was collected as they foraged for information related to the issues they followed, with serendipitous discovery as much part of the foraging process as was search. These chunks people retained represented a tiny fraction of the information they skimmed, triaged, and read on a daily basis: I frequently started my day with 400 documents with the expectation of maybe finding 3-10 sentences that I thought represented something interesting or important.
Developing a graph for an organization’s data layer(s) is a solvable problem. The degree to which that graph represents the organization’s knowledge is a completely different problem as that the organization’s explicit knowledge is a fraction of the tacit knowledge its people.
Even explicit knowledge is refined: finished written products, for example, are typically the result of idiosyncratic editing and review processes comprised of many people in many bureaucratic layers. These distributed products, however, do not capture the totality of the authors’, reviewers’, or editor’s research, thinking, or analysis. This is not good or bad, per se: it is. It has to do with professional and institutional standards as much as it has to do with personal and organizational brand management.
As LLMs typically strip out the metadata that people use to help them make sense of information, people involved in analytic work that requires a high degree of precision are Stuck between search that is broken and AIs that are frequently not aligned with either their professional expectations or standards.
What’s the Solution?
For the past year, I have been exploring this question in terms of creating more personalized AI experiences by focusing on providing third-party AIs with a better contextual understanding of me as user. The results have been promising.
Consider the following very unfair question that I posed to ChatGPT and Claude: What do I think about human-AI relations and AI companions? Claude gives a pretty succinct answer…
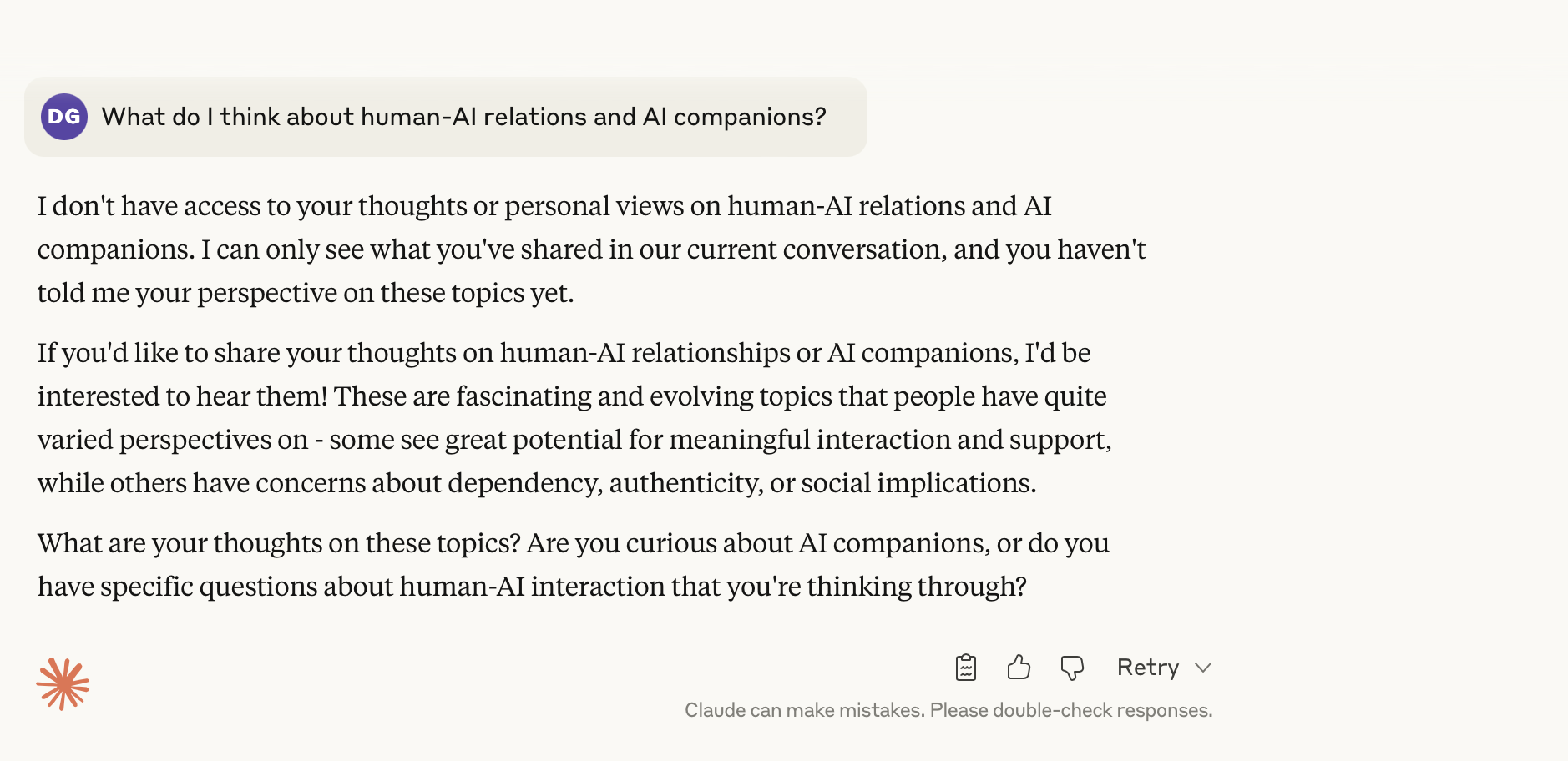
…and ChatGPT is both more expansive and inquisitive.

The bottom line is that neither knows.
Now, if I ask the same question to Claude with a context of what I know and what I think (using an AI-adjacent platform that I’m building), I get a very different response:
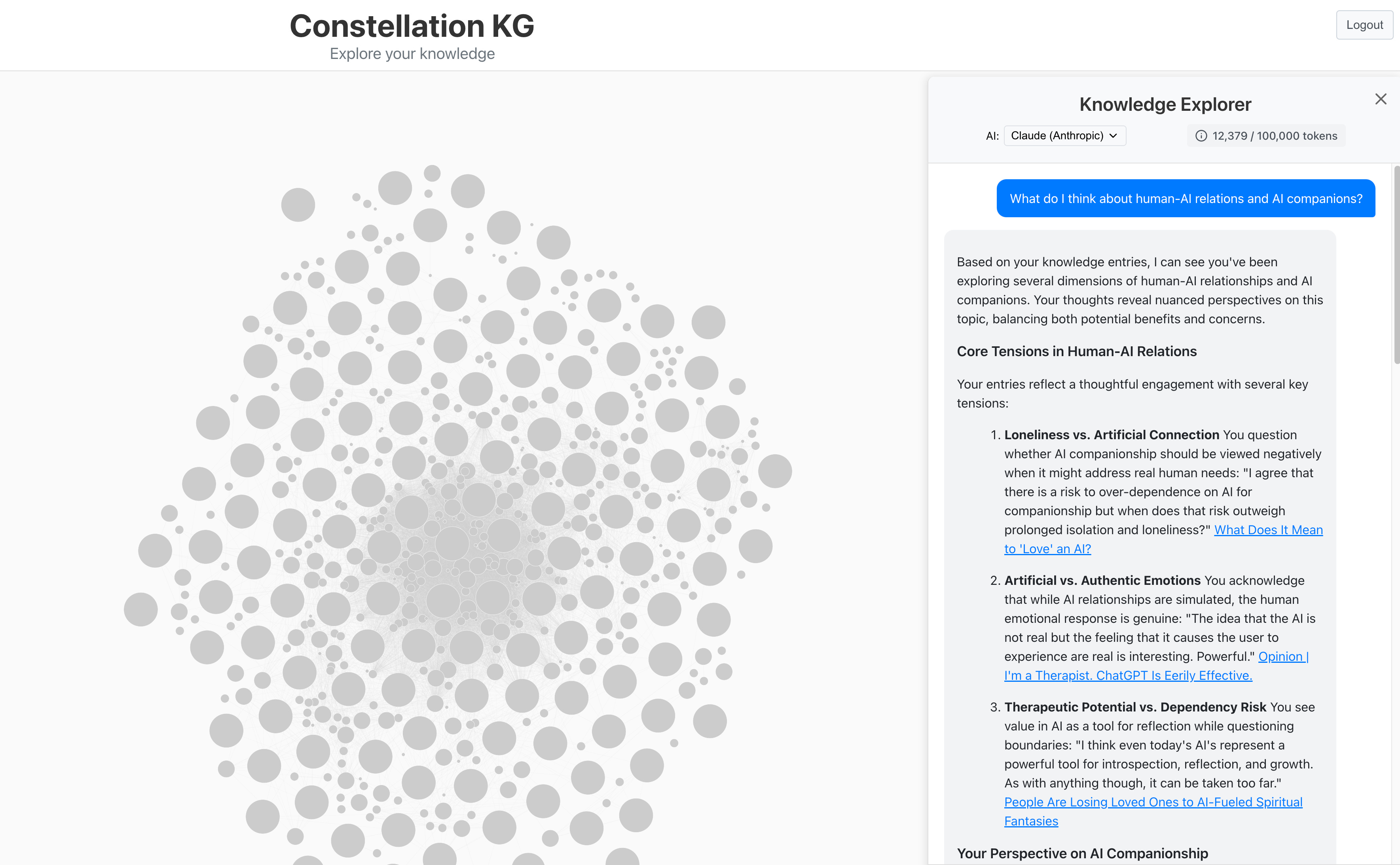
Better, right? As part of my information foraging, I tease out the information that it interesting to me and (sometimes) annotate it with an explanation of why I think it’s interesting. When I pass the information to an AI for analysis, it starts with a detailed map of my thinking.
This is only the beginning to more personalized AIs but I hope that it gives you a sense of what I see as the beginning of the art of the possible if the AI is provided with a contextual understanding of the user (in a way that respects both user privacy and the hygiene of the LLM). In any case…
The problem is that AIs, in their current forms, are not robust enough to handle a contextual understanding of me as a user: the graph used to inform this response is comprised of about 2,100 passages of text and about 1,100 thoughts that I have had reading those passages. I could not export this information to be processed by either ChatGPT or Claude because context windows are too small…and the graph I have built for demonstration purposes is narrowly scoped (it does not include all of my writing) and young (it’s less than a year old).
Circling Back to Context
So, I can demonstrate the value of giving a third-party AI a better contextual understanding of me as a user, even in that context is limited for several reasons (the time I can put into it [I’m still developing the platform after all – ha], the size of context windows, etc.) but what does all this mean for AI and how we use it in general?
I’d be incredibly excited to be the Chief AI Officer at a knowledge-producing organization. Recent headlines bemoaning the failure of AI pilots (“MIT report: 95% of generative AI pilots at companies are failing”) miss the point: the failures are as much a matter of corporate strategy as they are implementation strategy. Both can be corrected in ways that’ll produce interesting and useful experiences for internal users and external customers because the institution is uniquely qualified to contextualize the information it produces. Success will take work, and thankless work at that (absolutely no one likes data clean up) but this is a generational shift that positions the organization for future success.
From an organizational perspective, there might be questions of scalability and cost. Knowledge-producing organizations likely already have an IT infrastructure to support their internal users and external customers. Will a contextual AI be more expensive? I don’t know. As for scalability, it is another uncertainty but, again, the allocation of funds and resources to support enterprise IT likely exists. The questions are “Is that investment generating an acceptable return on investment?” and “Are the investments in enterprise IT positioning us for success today and in the future?”